Performance Comparison of NVIDIA Jetson AGX Thor and Orin 64GB
As the second installment of my blog series—made possible through the courtesy of NVIDIA headquarters—in which I am personally conducting an early review of the top-tier, pre-release Jetson model, the Jetson AGX Thor Developer Kit, I will benchmark performance using publicly available information (NVIDIA’s official spec sheets and developer pages) and the actual Jetson AGX Thor and Orin 64GB developer kits.
- NVIDIA Jetson AGX Thor Developer Kit — Unboxing and Seup: https://www.youtalk.jp/2025/08/26/jetson-thor-setup-en.html
The numbers in this article are based on public information and measurements using preview OS and software. With future official OS/software and optimization settings, real‑world performance will change. Also note the difference in metrics: Thor is primarily expressed in FP8/FP4 (Transformer Engine), while Orin mainly uses INT8 TOPS.
AI Performance Specifications Comparison
| Item | Jetson AGX Thor | Jetson AGX Orin 64GB |
|---|---|---|
| AI Performance | Up to 2,070 TFLOPS (FP4 sparse) | Up to 248 TOPS (INT8 sparse) |
| CPU | Arm Neoverse V3AE, 14 cores | Arm Cortex‑A78AE, 12 cores |
| Memory | 128 GB LPDDR5X (bandwidth 273 GB/s) | 64 GB LPDDR5 (bandwidth 204.8 GB/s) |
| GPU | 2,560 cores | 1,792 cores |
| Tensor | 96 cores | 56 cores |
| Multi‑instance | Supported | Not supported |
- https://www.nvidia.com/ja-jp/autonomous-machines/embedded-systems/jetson-thor/
- https://www.nvidia.com/ja-jp/autonomous-machines/embedded-systems/jetson-orin/
Thor emphasizes the Transformer Engine (FP8/FP4), giving it an advantage for generative AI/LLM workloads and larger Transformer models. Thor’s memory is 128 GB LPDDR5X (273 GB/s), which is twice the capacity of Orin 64GB (204.8 GB/s) and about 1.33× the bandwidth, providing more headroom for large model residency and buffer management.
Another notable difference is that Thor supports Multi‑Instance GPU (MIG) for partitioning and running workloads concurrently, which is advantageous in robot systems that need to safely run multiple models in parallel.
Ollama Setup
Ollama does not officially support Thor or JetPack 7 yet, so for the quick measurements I used a locally built container image of Ollama. For reproducibility, I include the Dockerfile below.
Special thanks to Mr. Yado at NVIDIA for supporting the Dockerfile preparation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
FROM nvcr.io/nvidia/pytorch:25.08-py3
ARG GO_VER=1.22.7
ENV CUDA_HOME=/usr/local/cuda
ENV OLLAMA_HOME=/opt/ollama
ENV GOPATH=/root/go
ENV PATH=/usr/local/go/bin:$PATH
ENV LD_LIBRARY_PATH=/opt/ollama/build/lib/ollama:$LD_LIBRARY_PATH
ENV GIN_MODE=release
# ---- Go ----
RUN curl -fsSL https://go.dev/dl/go${GO_VER}.linux-arm64.tar.gz -o /tmp/go.tgz \
&& rm -rf /usr/local/go \
&& tar -C /usr/local -xzf /tmp/go.tgz \
&& rm /tmp/go.tgz
# ---- Build Ollama ----
RUN git clone --depth=1 https://github.com/ollama/ollama.git ${OLLAMA_HOME}
WORKDIR ${OLLAMA_HOME}
RUN cmake -S . -B build \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_COMPILER="${CUDA_HOME}/bin/nvcc" \
-DCMAKE_CUDA_ARCHITECTURES=110 \
-DGGML_CUDA_ARCHITECTURES=110 \
&& cmake --build build -j"$(nproc)" \
&& go build -o ${OLLAMA_HOME}/ollama .
RUN ln -sf ${OLLAMA_HOME}/ollama /usr/local/bin/ollama
# ---- Entrypoint ----
RUN printf "%s\n" "#!/usr/bin/env bash" \
"set -e" \
"export LD_LIBRARY_PATH=\"/opt/ollama/build/lib/ollama:\${LD_LIBRARY_PATH}\"" \
"nohup /opt/ollama/ollama serve > /var/log/ollama.log 2>&1 & echo \"ollama serve started (logs: /var/log/ollama.log)\"" \
"exec \"\$@\"" \
> /usr/local/bin/start-ollama.sh \
&& chmod +x /usr/local/bin/start-ollama.sh
WORKDIR /workspace
ENTRYPOINT ["/usr/local/bin/start-ollama.sh"]
CMD ["bash"]
Once this Ollama pull request is merged, official support for Thor/JetPack 7 is expected: https://github.com/ollama/ollama/pull/11999.
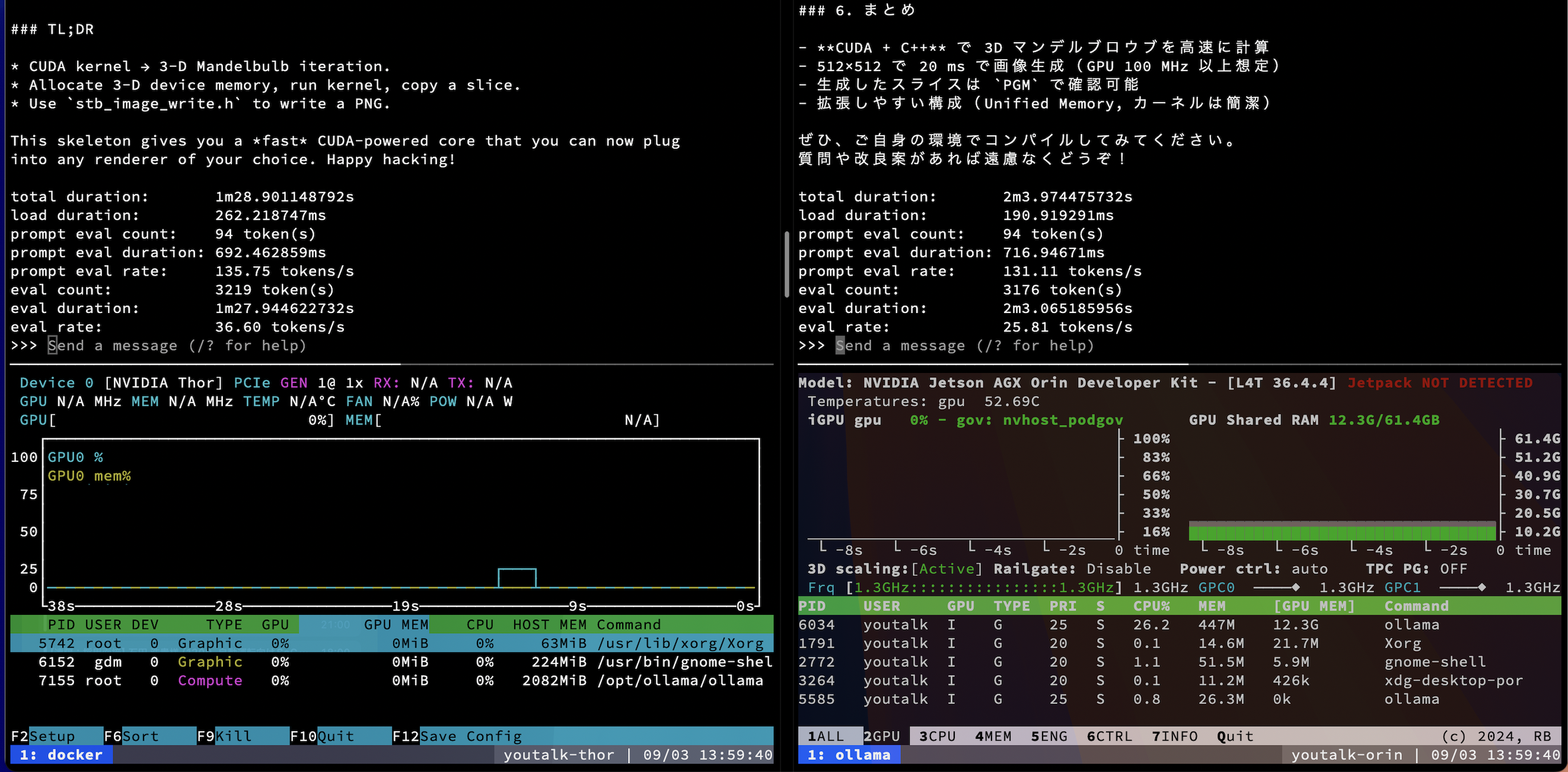
gpt-oss:20b Performance Comparison
I ran gpt-oss:20b on Ollama with the same prompt and --verbose, and compared the prompt eval rate and eval rate printed at the end. On Thor I used the custom container above; on Orin I used the official Ollama setup.
| Metric | Thor (custom container build) | Orin (official setup) |
|---|---|---|
| prompt eval count | 94 tokens | 94 tokens |
| prompt eval duration | 0.692 s | 0.717 s |
| prompt eval rate | 135.75 tok/s | 131.11 tok/s |
| eval count | 3,219 tokens | 3,176 tokens |
| eval duration | 87.94 s | 123.07 s |
| eval rate | 36.60 tok/s | 25.81 tok/s |
The gap felt smaller than I expected. The +42% in eval rate roughly matches Thor’s memory bandwidth advantage (273 GB/s) over Orin (204.8 GB/s). Decoding of large models tends to be memory‑bandwidth bound, so the potential compute advantage (TE/FP4) does not surface as clearly.
There is also a possibility that MXFP4 was not actually used. The gpt-oss:20b models are often distributed as GGUF quantizations (mostly INT4/INT8), which differ from the FP8/FP4 data paths presumed by Thor’s Transformer Engine. On Jetson today, Ollama/llama.cpp likely runs a generic CUDA/cuBLAS path rather than TE‑specific kernels, so Thor’s “FP4/FP8 compute advantage” does not fully appear and the improvement stays near the bandwidth difference.
gpt-oss:120b Performance Comparison
Under similar conditions with gpt-oss:120b, Thor completed generation while Orin aborted during execution. From the logs, out‑of‑memory (OOM) is the likely cause.
| Metric | Thor (custom container build) | Orin (official setup) |
|---|---|---|
| prompt eval count | 94 tokens | — |
| prompt eval duration | 1.336 s | — |
| prompt eval rate | 70.34 tok/s | — |
| eval count | 4,652 tokens | — |
| eval duration | 265.998 s | — |
| eval rate | 17.50 tok/s | — |
With GGUF quantization, Thor (128 GB) can keep the model resident and allocate working memory, whereas Orin (64 GB) is tight on usable memory; once you include paging and kernel workspace, it likely ran out of headroom and hit OOM. In the screen‑capture video, Orin’s GPU MEM rises to around 56 GB, suggesting the remaining headroom was insufficient and the allocator/kernels failed.
Compared with Thor at 20B, eval rate drops to 17.50 tok/s. As the parameter size increases, memory bandwidth and cache efficiency dominate further, lowering throughput. As with 20B, it is likely that the FP8/FP4 path assumed by the Transformer Engine was not used, so Thor’s potential is not fully realized here.
Again, it’s remarkable that gpt-oss:120b—roughly on par with OpenAI o4‑mini—can run under 100 W without worrying about a 24‑hour limit. The runtime speed feels comparable to using ChatGPT, with little practical friction. I plan to use it as a backend for Codex CLI going forward.
Upcoming Posts in the Series
Starting next time, I’ll switch gears to building a Hardware‑in‑the‑Loop robot simulation environment that combines NVIDIA Isaac Sim with Thor, and introduce a pipeline that processes real‑time video streams from the simulator on Thor.
I also picked up a desktop with an NVIDIA RTX 5080 for this experiment.
NVIDIA RTX 5080、Intel Core i9、メモリ64GBのデスクトップPCを調達したので、自宅開発をさらに加速させるぞ。
— youtalk 改訂新版 #ROS2ではじめよう (@youtalk) August 17, 2025