NVIDIA Jetson AGX ThorとOrin 64GBの性能比較
NVIDIA本社のお計らいで、個人的に発売前のJetson最上位モデルであるJetson AGX Thor開発者キットを先行レビューしているブログシリーズの第2弾として、公開情報(NVIDIA公式のスペックシート/開発者向けページ)とJetson ThorとOrin 64GBの開発者キット実機を使って性能をベンチマークします。
本記事の数値は公開情報ベースとプレビュー版OS、ソフトウェアを使った値です。今後の正式版OS、ソフトウェアや最適化設定により、実運用時の性能は変わります。 指標の違いにも注意してください。ThorはFP8/FP4系(Transformer Engine)中心の表記、OrinはINT8のTOPS表記が中心です。
AI性能周りの仕様比較
| 項目 | Jetson AGX Thor | Jetson AGX Orin 64GB |
|---|---|---|
| AI性能 | 最大2,070TFLOPS(FP4スパース) | 最大248TOPS(INT8スパース) |
| CPU | Arm Neoverse V3AE 14コア | Arm Cortex‑A78AE 12コア |
| メモリ | 128GB LPDDR5X(帯域273GB/s) | 64GB LPDDR5(帯域204.8GB/s) |
| GPU | 2560コア | 1792コア |
| Tensor | 96コア | 56コア |
| マルチインスタンス | 対応 | 未対応 |
- https://www.nvidia.com/ja-jp/autonomous-machines/embedded-systems/jetson-thor/
- https://www.nvidia.com/ja-jp/autonomous-machines/embedded-systems/jetson-orin/
ThorはFP8/FP4を前提にしたTransformer Engineを前面に出しており、生成AI/LLM系や大きめなトランスフォーマモデルでの推論に優位性があります。 また、Thorのメモリは128GB LPDDR5X(273GB/s)で、Orin 64GB(204.8GB/s)からメモリ容量2倍、帯域も約1.33倍に増加。大規模モデルの常駐やバッファの取り回しで余裕が出ます。
また、特徴的な違いとして、Thorはマルチインスタンス GPUでワークロードの分割・同時実行に対応しています。複数モデルを安全に併走させたいロボット構成で有利です。
Ollamaセットアップ
OllamaはまだThorやJetPack 7を公式サポートしていないので、実測速報の検証用にローカルでコンテナビルドしたOllamaのDockerイメージを使用しました。再現性のために、利用したDockerfileを以下に掲載します。
Dockerfile作成にはNVIDIAの矢戸様にサポートいただきました。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
FROM nvcr.io/nvidia/pytorch:25.08-py3
ARG GO_VER=1.22.7
ENV CUDA_HOME=/usr/local/cuda
ENV OLLAMA_HOME=/opt/ollama
ENV GOPATH=/root/go
ENV PATH=/usr/local/go/bin:$PATH
ENV LD_LIBRARY_PATH=/opt/ollama/build/lib/ollama:$LD_LIBRARY_PATH
ENV GIN_MODE=release
# ---- Go ----
RUN curl -fsSL https://go.dev/dl/go${GO_VER}.linux-arm64.tar.gz -o /tmp/go.tgz \
&& rm -rf /usr/local/go \
&& tar -C /usr/local -xzf /tmp/go.tgz \
&& rm /tmp/go.tgz
# ---- Build Ollama ----
RUN git clone --depth=1 https://github.com/ollama/ollama.git ${OLLAMA_HOME}
WORKDIR ${OLLAMA_HOME}
RUN cmake -S . -B build \
-DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_COMPILER="${CUDA_HOME}/bin/nvcc" \
-DCMAKE_CUDA_ARCHITECTURES=110 \
-DGGML_CUDA_ARCHITECTURES=110 \
&& cmake --build build -j"$(nproc)" \
&& go build -o ${OLLAMA_HOME}/ollama .
RUN ln -sf ${OLLAMA_HOME}/ollama /usr/local/bin/ollama
# ---- Entrypoint ----
RUN printf "%s\n" "#!/usr/bin/env bash" \
"set -e" \
"export LD_LIBRARY_PATH=\"/opt/ollama/build/lib/ollama:\${LD_LIBRARY_PATH}\"" \
"nohup /opt/ollama/ollama serve > /var/log/ollama.log 2>&1 & echo \"ollama serve started (logs: /var/log/ollama.log)\"" \
"exec \"\$@\"" \
> /usr/local/bin/start-ollama.sh \
&& chmod +x /usr/local/bin/start-ollama.sh
WORKDIR /workspace
ENTRYPOINT ["/usr/local/bin/start-ollama.sh"]
CMD ["bash"]
なお、こちらのOllamaのプルリクエストがマージされるとThorやJetPack 7に公式対応する予定です。
gpt-oss:20b 性能比較
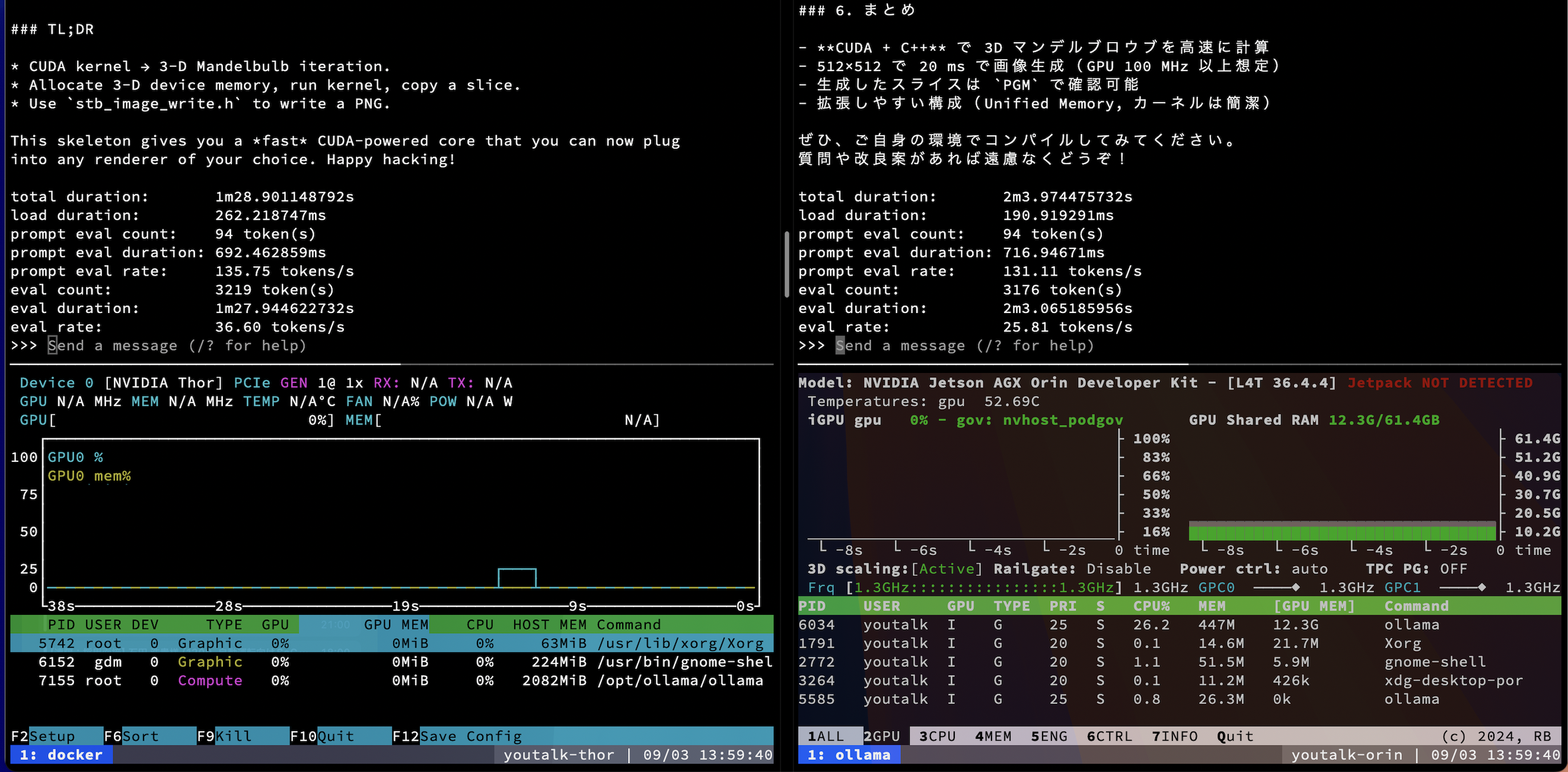
今回はOllamaでgpt-oss:20bを同一プロンプトで --verbose 付きで実行し、実行後に出力されるprompt eval rateとeval rateを比較しました。Thor側は上記コンテナを使用し、Orin 側はOllama公式セットアップのままです。
| 指標 | Thor(自前コンテナビルド) | Orin(公式セットアップ) |
|---|---|---|
| prompt eval count | 94 tokens | 94 tokens |
| prompt eval duration | 0.692 s | 0.717 s |
| prompt eval rate | 135.75 tok/s | 131.11 tok/s |
| eval count | 3,219 tokens | 3,176 tokens |
| eval duration | 87.94 s | 123.07 s |
| eval rate | 36.60 tok/s | 25.81 tok/s |
僕の予想よりは体感上、差が思ったほど開きませんでした。 eval rate の伸び(+42%)はThorのメモリ帯域(273GB/s)が Orin(204.8GB/s)より大きいこととおおむね整合します。大規模モデルのデコードはメモリ帯域支配になりやすく、計算器(TE/FP4)の潜在性能差がそのまま出にくいようです。
また、MXFP4を使えていない可能性が残ります。今回の gpt-oss:20b はGGUF形式の量子化(多くはINT4/INT8系)で配布されることが多く、ThorのTransformer EngineのMXFP4/FP8前提の計算パスとはデータ形式が異なります。Ollama/llama.cppのJetson向け実装だと、少なくとも現時点ではTransformer Engine専用カーネルを使わず、CUDA/cuBLASベースの汎用パスで動いている可能性が高いです。結果として、Thorの「FP4/FP8の計算性能優位」が表に出にくく、帯域差に近い伸びに留まったと考えています。
gpt-oss:120b 性能比較
gpt-oss:120b で同様の条件を試したところ、Thorは生成が完走した一方、Orinは実行中に異常終了しました。ログの状況から、メモリ不足(OOM)が濃厚です。
| 指標 | Thor(自前コンテナビルド) | Orin(公式セットアップ) |
|---|---|---|
| prompt eval count | 94 tokens | — |
| prompt eval duration | 1.336 s | — |
| prompt eval rate | 70.34 tok/s | — |
| eval count | 4,652 tokens | — |
| eval duration | 265.998 s | — |
| eval rate | 17.50 tok/s | — |
Thor(128GB)はGGUF 量子化ならモデル常駐+ワーク領域を確保できる一方、Orin(64GB)は使用可能メモリがタイトで、ページングや、カーネルワークスペースを含めると余裕がなく、OOM に至った可能性が高いです。スクリーンキャプチャ動画でもOrin側の GPU MEM が 56GB 付近まで上がっており、残りでカーネルやアロケータが破綻したと推測します。
Thorのgpt-oss:20bのときとの比較になりますが、 eval rate は17.50 tok/sと 20B時より低下しています。パラメータ規模増加に伴いメモリ帯域・キャッシュ効率がさらに支配的となり、スループットが下がったとみられます。20Bと同様に、Transformer Engine前提のFP8/FP4パスを通っていない可能性が高く、Thorの潜在性能が引き出せていないと考えています。
改めて、OpenAI o4-mini相当の性能を持つgpt-oss:120bが100W未満で24時間リミットを気にすることなく稼働させることができるのは、非常に素晴らしいことです。実行速度もChatGPTを使っている時と遜色のない速度で動き、実用上の違和感はほぼありません。今後はCodex CLIのバックエンドにも使っていきたいと思います。
今後の連載予定
次回からは話を変えて、NVIDIA Isaac SimとThorを組み合わせたHardware-in-the-Loopロボットシミュレーション環境の構築と、シミュレータからのリアルタイム映像ストリームをThorで処理するパイプラインを紹介していきます。
このためにNVIDIA RTX 5080のデスクトップも調達しました。
NVIDIA RTX 5080、Intel Core i9、メモリ64GBのデスクトップPCを調達したので、自宅開発をさらに加速させるぞ。
— youtalk 改訂新版 #ROS2ではじめよう (@youtalk) August 17, 2025